
Machine Learning(ML) 모델의 성능을 평가하는 것은 모델이 주어진 작업을 얼마나 잘 수행하는지를 확인하는 과정입니다. 모델의 성능을 평가하기 위해 다음과 같은 여러 지표들을 사용할 수 있습니다.
정확도(Accuracy): 모델이 정확하게 분류한 샘플의 비율로 계산됩니다. 이는 분류 작업에서 가장 일반적으로 사용되는 평가 지표입니다. 하지만 데이터의 불균형이 있을 경우 정확도만으로는 모델의 성능을 정확히 평가하기 어려울 수 있습니다.
오차 행렬(Confusion Matrix): 이진 분류에서 모델의 예측 결과와 실제 클래스를 비교하여 예측값에 따라 적절한 위치에 샘플을 배치한 행렬입니다. 오차 행렬을 통해 정확한 예측, 오진, 거짓 음성 등의 정보를 확인할 수 있습니다. 이를 기반으로 다양한 평가 지표를 계산할 수 있습니다.
정밀도(Precision)와 재현율(Recall): 이진 분류 (binary classification) 에서 모델이 양성 클래스를 얼마나 정확하게 예측하는지에 대한 지표입니다. 정밀도는 실제로 양성인 것들 중에서 모델이 양성으로 예측한 비율을, 재현율은 실제로 양성인 것들 중에서 모델이 양성으로 예측한 비율을 나타냅니다. 정밀도와 재현율은 서로 상충 관계에 있으므로 작업의 목적과 중요성에 따라 적절한 평가 기준을 선택해야 합니다.
F1 점수(F1 Score): 정밀도와 재현율의 조화 평균으로 계산되는 값입니다. F1 점수는 정밀도와 재현율의 균형을 고려한 평가 지표로 사용됩니다.
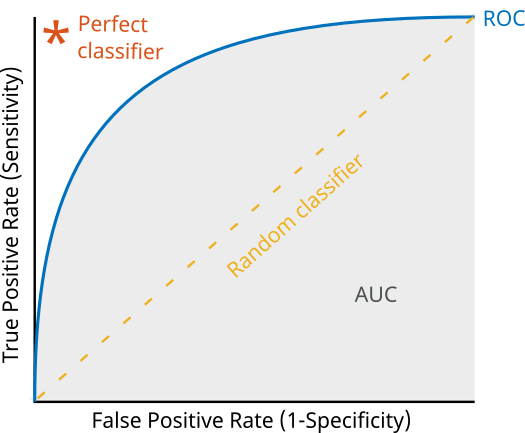
ROC 곡선과 AUC(Area Under the Curve): 이진 분류에서 모델의 성능을 시각화하고 평가하기 위해 사용됩니다. ROC(Receiver Operating Characteristic) 곡선은 분류 임계값을 변화시키면서 진짜 양성 비율(TPR)에 대한 거짓 양성 비율(FPR)의 변화를 나타냅니다. AUC는 ROC 곡선 아래의 면적으로 계산되며, 모델의 분류 성능을 나타내는 값입니다. AUC 값이 1에 가까울수록 성능이 우수합니다.
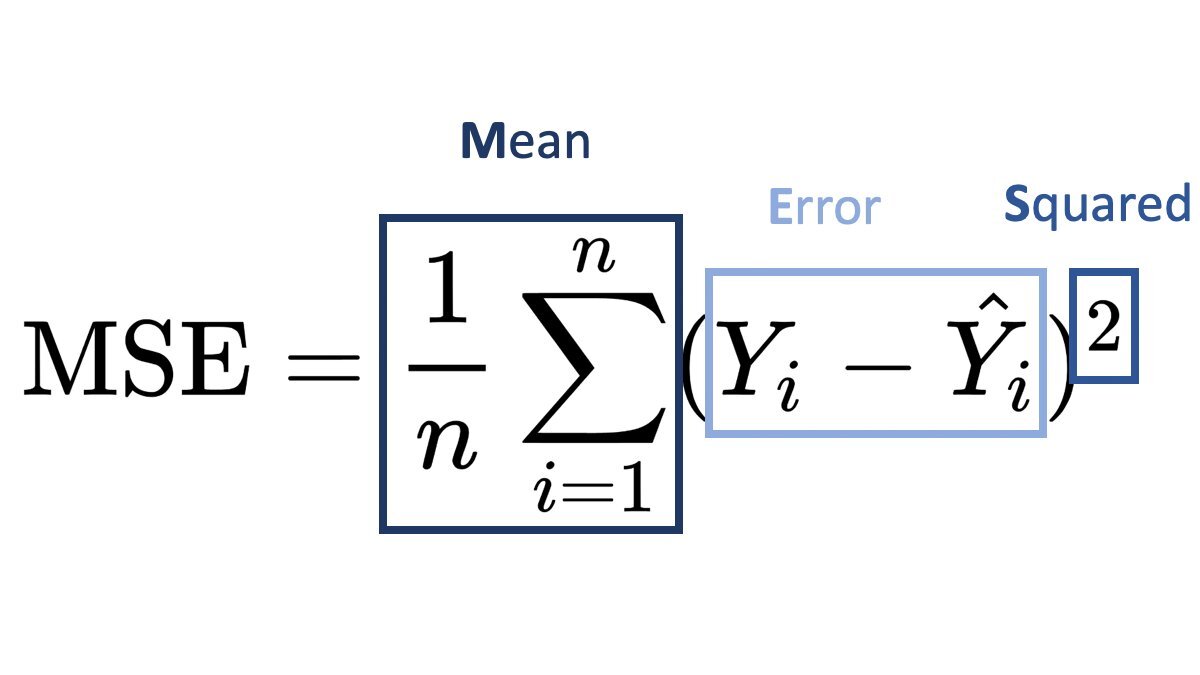
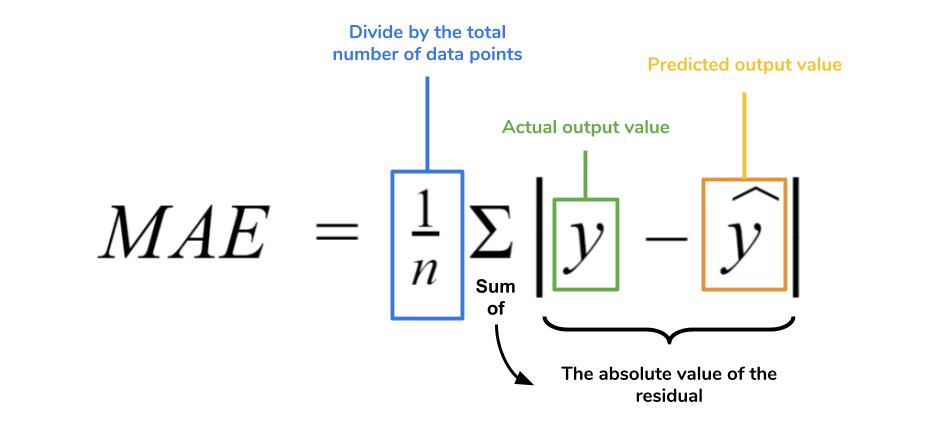
회귀의 경우 평균 제곱 오차(Mean Squared Error), 평균 절대 오차(Mean Absolute Error), 결정 계수(R-Squared) 등이 일반적으로 사용되는 평가 지표입니다.
모델의 성능을 평가할 때는 작업의 특성과 요구사항을 고려하여 적절한 평가 지표를 선택해야 합니다. 또한 교차 검증(Cross-validation)을 통해 모델의 일반화 성능을 평가하는 것이 좋습니다. 이를 통해 모델의 성능을 정량적으로 평가하고, 개선을 위한 방향을 찾을 수 있습니다.
'Machine Learning' 카테고리의 다른 글
| generalization error 란 무엇인가? (0) | 2023.06.03 |
|---|---|
| 머신러닝 모델들은 무엇이 있을까? (0) | 2023.05.25 |
| 한분야의 전문가가 Data Science를 배워야 하는 이유 (0) | 2023.05.24 |
| Data Science의 대표적인 도구들은? (0) | 2023.05.24 |
| labelling 되어있지 않은 대량의 data를 해석하는 방법 (0) | 2023.05.24 |



